In the world of Application-Specific Integrated Circuit (ASIC) design, Engineering Change Orders (ECOs) are an inevitable part of the development cycle. While essential for bug fixes or feature enhancements, an inefficient ECO can lead to significant delays and gate count bloat. A critical aspect of a successful ECO is minimizing the netlist patch size, which directly impacts implementation time, verification effort, and area.
This article explores a common scenario in RTL (Register-Transfer Level) ECO where a seemingly simple change can result in a disproportionately large netlist modification. We'll present an optimized approach, guided by the principles that GOF AI agents will leverage to produce minimal patches.
Consider the following initial Verilog RTL:
output [8:0] adval;
reg [8:0] adval;
always @(posedge clk or negedge rst) begin
if(~rst) adval <= 9'h0;
else adval <= dspin_i * dasp_r + twik;
end
Now, a new requirement dictates subtracting a value udc[2:0] from the calculated adval. A straightforward, but often inefficient, approach might be to directly modify the arithmetic expression inside the always block:
Naive First Verilog Change:
output [8:0] adval;
reg [8:0] adval;
always @(posedge clk or negedge rst) begin
if(~rst) adval <= 9'h0;
else adval <= dspin_i * dasp_r + twik - udc[2:0]; // Direct modification
end
While this change correctly implements the desired functionality, it often leads to a **very large netlist patch size** after synthesis and ECO. The reason lies in how complex arithmetic operations, especially multipliers, are synthesized.
dspin_i * dasp_r is typically synthesized into highly optimized, complex structures like Wallace trees. Modifying an input to this arithmetic block, even with a simple subtraction, often forces the synthesis tool to *tear apart and rebuild* a significant portion of this optimized tree. This results in a much higher gate count change (e.g., 100+ gates) than intuitively expected.
The core principle for minimizing patch size in such scenarios is to preserve existing, highly optimized combinational logic cones (like multipliers) feeding registers. Instead of altering the core arithmetic, we can isolate the new operation and add it at the output of the existing register structure.
Here's the proposed optimized RTL change:
output [8:0] adval;
// 1. Rename the original register to an internal signal
reg [8:0] adval_int;
// 2. Create a new register to pipeline the new 'udc' input
// This ensures the subtraction happens on data from the same clock cycle.
reg [2:0] udc_d;
// 3. Perform the subtraction combinationally after the registers
// This uses a small subtractor (approx 9-10 gates) and leaves the
// complex multiplier logic untouched.
assign adval = adval_int - udc_d;
// 4. Keep the original logic block EXACTLY as it was (renamed target)
always @(posedge clk or negedge rst) begin
if(~rst) adval_int <= 9'h0;
else adval_int <= dspin_i * dasp_r + twik;
end
// 5. Register the new input
always @(posedge clk or negedge rst) begin
if(~rst) udc_d <= 3'b0;
else udc_d <= udc[2:0];
end
adval_int remains untouched. The ECO tool only needs to connect to the output of this existing structure.adval_int register.udc_d to pipeline the udc input.adval output port.The following diagram illustrates how a GOF AI agent can guide this process, iterating from a naive change to an optimized proposal, focusing on minimal netlist patch generation:
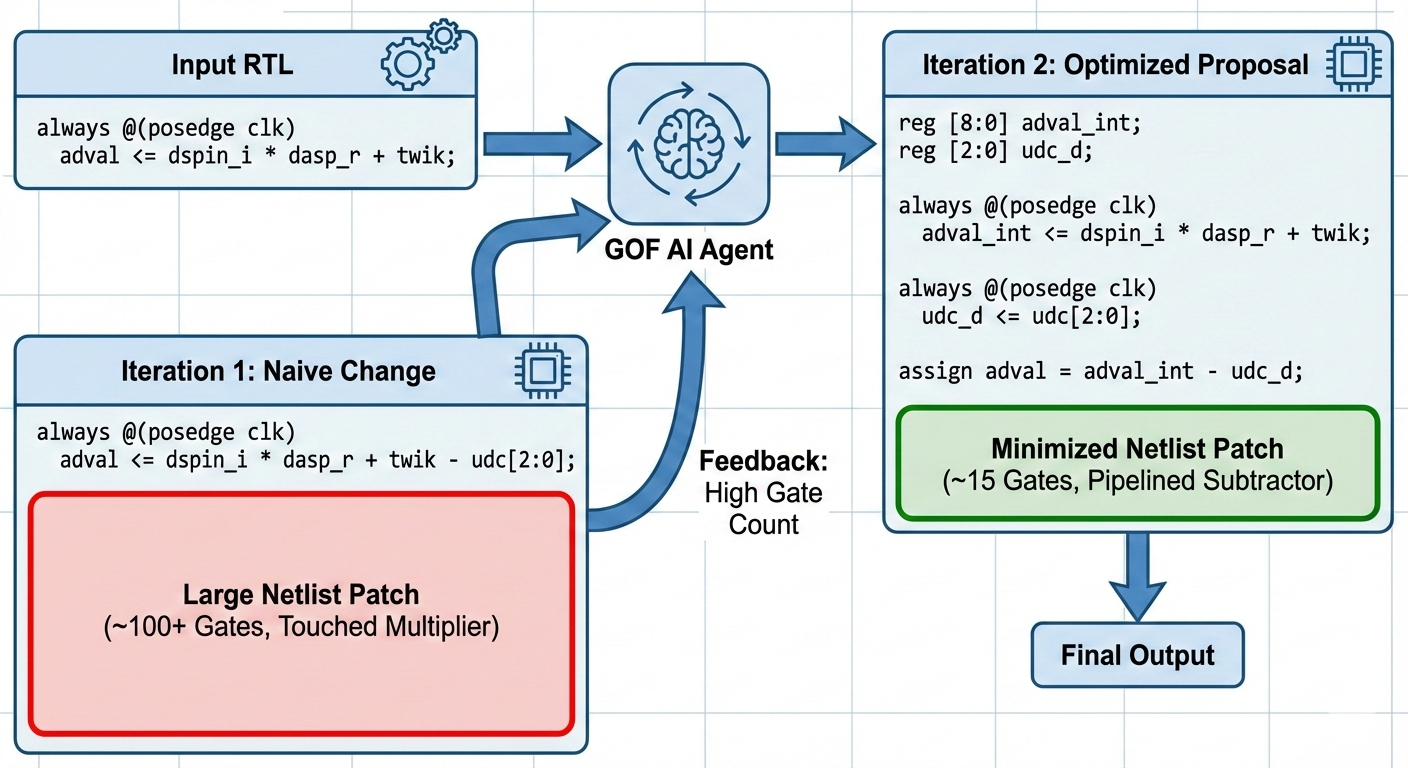
In this flow, the GOF AI agent analyzes the impact of RTL changes on the synthesized netlist. It can detect that the "Naive Change" (Iteration 1) results in a high gate count patch due to disrupting optimized arithmetic blocks. Leveraging its understanding of synthesis and ECO principles, it then proposes an "Optimized Proposal" (Iteration 2) that isolates the change, leading to a significantly minimized netlist patch.
Minimizing netlist patch size is crucial for efficient ECO implementation. By understanding how synthesis tools optimize complex logic, particularly arithmetic components, designers can craft RTL changes that preserve existing optimizations. Tools like GOF AI are being developed to automate this process, allowing AI agents to analyze RTL, propose optimal changes, and achieve the smallest possible netlist patch size through iterative refinement, thereby accelerating the chip design cycle.